
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 대전 웨딩홀 가격
- 대전 피로연장 넉넉한 웨딩홀
- 코린이블로그9일차 #알고리즘공부 #C언어
- 코린이블로그4일차 #알고리즘공부 #C언어
- 코린이블로그2일차 #알고리즘공부 #C언어
- AIBootcamp
- 대전스냅
- 대전본식스냅
- 대전 웨딩홀 추천
- CLI
- 대전 웨딩홀 비교
- 대전결혼준비
- 대전스냅추천
- codestates
- 여백스냅
- 대전본식스냅추천
- 대전예식
- AI부트캠프
- 화담필름
- 웅장한 웨딩홀
- 코린이블로그8일차 #알고리즘공부 #C언어
- 팔레드오페라웨딩홀
- 대전본식dvd
- 대전 팔레드오페라 후기
- 팔레드오페라 웨딩홀 계약 후기
- 2주차
- 1주차
- 파이썬
- 코드스테이츠
- 코린이블로그17일차 #알고리즘공부 #C언어
- Today
- Total
찰리의 놀이터
[DB] 열 기반 데이터베이스 vs 행 기반 데이터베이스 본문
행 기반 데이터베이스(Row Oriented Database)
행 지향 데이터베이스라고도 부릅니다.
일반적으로 우리가 사용하는 Oracle, MySQL, PostgreSQL와 같은 일반적인 데이터베이스가 행 기반 데이터베이스에 해당됩니다.
데이터를 행 단위로 추가하는 것을 의미하며, 레코드 단위의 읽고 쓰기에 최적화 되어있습니다.
데이터 검색을 고속화하기 위해 인덱스를 사용합니다.
인덱스가 없다면 모든 데이터를 로드해야 원하는 데이터를 찾을 수 있어서 데이터 I/O가 많이 발생하고 성능이 저하됩니다.
레코드 단위로 데이터가 저장되어 있기 때문에 필요없는 열까지 디스크로부터 로드됩니다.

위 그림과 같이 행 기반 데이터베이스는 화살표처럼 디스크에 한 행 씩 저장되는 형태입니다.
데이터를 추가하면

위 그림과 같이 한 행씩 끝에 추가되는 형태입니다.
추가된 행을 디스크에 추가하려면 원본 데이터의 끝에 추가하면 됩니다.

테이블에서 모든 사람의 평균 연령을 얻고싶다고 가정했을 때, 전체 행에 접근하게 됩니다.
디스크가 너무 작아서 하나의 디스크에 하나의 행만 저장할 수 있다고 가정했을 때는 상황이 더욱 악화됩니다.
모든 단일 디스크에 접근을 해야하기 때문입니다.
또한 우리가 필요한 열은 Age 뿐인데 행 기반 데이터베이스는 행 단위로 불러오므로 Name, City와 같이 필요없는 열 또한 불러오게 됩니다.
이로인해, 디스크 I/O에서 많은 부하가 발생하고, 성능 또한 낮아질 수 밖에 없습니다.
열 기반 데이터베이스(Column Oriented Database)
열 지향 데이터베이스라고도 합니다.
Amazon Redshift, Google Bigquery, Teradata, Snowflake, Cassandra, HBase 등이 있습니다.
Column(열)을 기반으로 하기 때문에 필요한 열만 로드하므로 디스크I/O를 줄이고, 높은 성능을 가지고 있습니다.
또한, 같은 열에는 유사한 데이터가 반복되기 때문에, 행 기반 데이터베이스보다 훨씬 작게 압축할 수 있습니다.

위 그림과 같이 열 기반 데이터베이스는 앞쪽에 Name 열, 중간에는 City 열, 끝쪽에는 Age 별로 나누어 저장하게 됩니다.

열 기반 데이터베이스는 각 Column별로 추가되어야할 자리를 찾는 과정이 필요합니다.
따라서 조회작업의 성능은 행 기반 데이터베이스에 비해 높은 반면에 값을 삽입, 수정, 삭제하는 과정에서는 레코드의 수도 많고, 이에 따라 인덱스가 리빌드 되어야하는 과정이 포함되어 있어 성능이 현저하게 낮습니다.
이 경우에는 행 기반 데이터베이스가 더욱 성능이 뛰어날 뿐만 아니라, 완전성 측면에서 안전합니다.
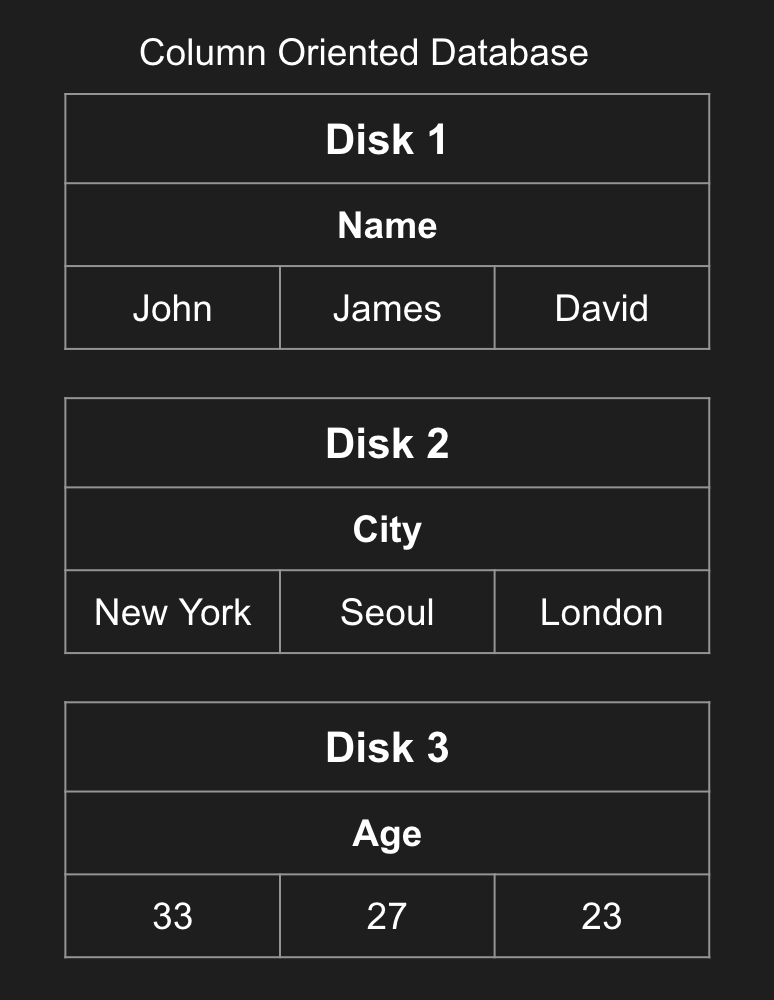
같은 데이터를 열 기반 데이터베이스에 저장할 경우 평균 연령 데이터를 구하기 위해서는 Disk 3에만 접근을 하면 되므로 확실히 접근해야하는 디스크 수가 적은 것을 알 수 있습니다.
정리
Row Oriented Database
기간계 시스템이라고 부르는 OLTP 환경(Insert, Update, Delete 작업이 빈번한 환경)에서 유리하게 작용합니다.
장점
- row 삽입, 수정, 삭제 시 매우 간편합니다.
- 행 단위로 데이터를 조회할 경우 성능을 보장합니다.
단점
- 특정 필드(열) 데이터 집합을 조회할 때 성능이 떨어집니다.
Column Oriented Database
분석계 시스템이라고 부르는 OLAP 환경(Select 작업이 빈번한 환경)에서 유리하게 작용합니다.
장점
- 특정 필드 데이터 집합을 조회할 때 성능이 뛰어나며, 추가 메모리 할당없이 작업을 수행할 수 있습니다.
- 추가메모리 할당이 없다 : 하나의 테이블에 모든 데이터가 들어있어 다수의 테이블을 키로 연결하는 JOIN 구문을 사용하지 않고 하나의 대상 테이블에 단일 쿼리를 사용하여 데이터를 가져옵니다.
단점
- 데이터 추가 작업을 수행할 때, 각 데이터의 마지막 위치를 확인하는 작업이 필요하며, 데이터 삽입, 수정, 삭제 시 성능이 떨어집니다.
'DataBase' 카테고리의 다른 글
| [Django] 쿼리셋(QuerySet) 객체별 접근 방식 (0) | 2023.05.04 |
|---|---|
| [DB] CAP Theorem(캡 정리) (0) | 2023.03.13 |
| [DB] 데이터베이스 기본 (1) | 2023.02.22 |

