
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 대전 웨딩홀 비교
- 코린이블로그2일차 #알고리즘공부 #C언어
- 코드스테이츠
- 파이썬
- 코린이블로그4일차 #알고리즘공부 #C언어
- 코린이블로그8일차 #알고리즘공부 #C언어
- 대전 팔레드오페라 후기
- 대전본식dvd
- 대전스냅
- 대전결혼준비
- 화담필름
- 대전 웨딩홀 추천
- 2주차
- 대전본식스냅
- AI부트캠프
- AIBootcamp
- 대전스냅추천
- 1주차
- 코린이블로그9일차 #알고리즘공부 #C언어
- codestates
- 대전예식
- 대전본식스냅추천
- CLI
- 팔레드오페라 웨딩홀 계약 후기
- 코린이블로그17일차 #알고리즘공부 #C언어
- 웅장한 웨딩홀
- 팔레드오페라웨딩홀
- 대전 피로연장 넉넉한 웨딩홀
- 여백스냅
- 대전 웨딩홀 가격
- Today
- Total
찰리의 놀이터
Section 2 Project 회고 본문
Codestates AI Bootcamp Section 2 Project 회고
1. 프로젝트 설명
이번 프로젝트는 주제를 골라서 탐색적 데이터 분석(Exploratory Data Analysis), 전처리(Preprocessing), 특성 공학(Feature Engineering), 가설 검정(Hypothesis Testing), 머신 러닝 모델링(Machine Learning Modeling), 특성 중요도 계산(Feature Importance Calculating), 시각화(Visualization) 등 머신 러닝 모델링을 위한 준비와 실행, 결과 보고의 의미를 담고 있다.
2. 프로젝트 진행과정
(1) 데이터 선택
내가 프로젝트에서 고른 데이터는 주식 데이터
https://dacon.io/competitions/official/235800/overview/description
주식 종료 가격 예측 Pre Competiton(with.데이커) - DACON
1.주제 KOSPI-200과 KOSDAQ-200의 주어진 기간에 마지막으로 거래된 가격(종가)를 예측하는 경진대회입니다. 2.주식 종료 가격 예측 Pre Competition 설명 안녕하세요, 데이커(가칭) 여러분 🤗 (설문조사 링
dacon.io
주식 데이터를 고른 이유를 설명하자면
1) 금융 데이터
- 금융 업계, FINTECH에 관심이 가고 관심 있는 분야의 도메인 지식을 늘리기 위함이다.
2) 공개적으로 점수 및 랭크를 확인할 수 있는 대회
- 혼자서 진행하고 점수를 보며 만족하는 것보다 경쟁 상대가 있었으면 좋겠다. 생각 했고 데이콘 주식 종가 예측 대회에 참가했다.
3) 시계열 데이터
- 시계열 데이터에 대한 건 아직 배운 적은 없지만 예습과 난이도를 올릴 수 있는 장치였으면 좋겠다고 생각했다.
(2) EDA
대회와 조금 다른 노선을 타기 시작했다.
대회에서는 제출 파일에 정해진 종목 번호를 이용해서 모델링을 하는 것이다.
내가 진행한 방향은 코스피(KOSPI) 지수 그 자체를 예측하는 거였다.
KOSPI와 KOSDAQ을 제외한 해외 주요 주식 정보도 불러올 수 있도록 대회에서 방법을 알려준다.
import FinanceDataReader as fdr
stock = fdr.DataReader('종목번호', start = '시작날짜', end = '종료날짜')FinanceDataReader 모듈을 사용해서 주식 데이터를 불러올 수 있다.
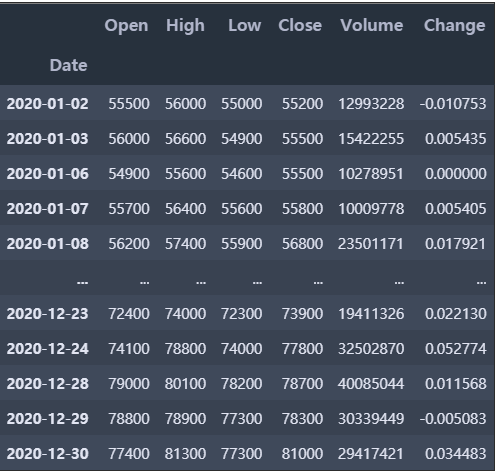
불러오고 나면 이렇게 시작가, 고가, 저가, 종가, 거래량, 변동률의 형식이 나온다.
이 때부터 다른 노선을 타기 시작했는데 왜?
사실 최종적인 목표는 같았지만, 나는 코스피 자체를 먼저 예측해보고 싶었다.
코스피는 뭔가 개별 사주보다는 큰 범위니까 수월하지 않을까 싶기도 했다. 오만 했지
그래서 EDA는?
우선 종가는 거래량과 꽤나 관련이 있지 않을까? 라는 가설을 세웠다.
→ 선형회귀 확인했다.

근데 또 궁금해졌다.
다른 특성은?
조금 귀찮아서 특성 상관 계수(Correlation Coefficient)를 확인했다.
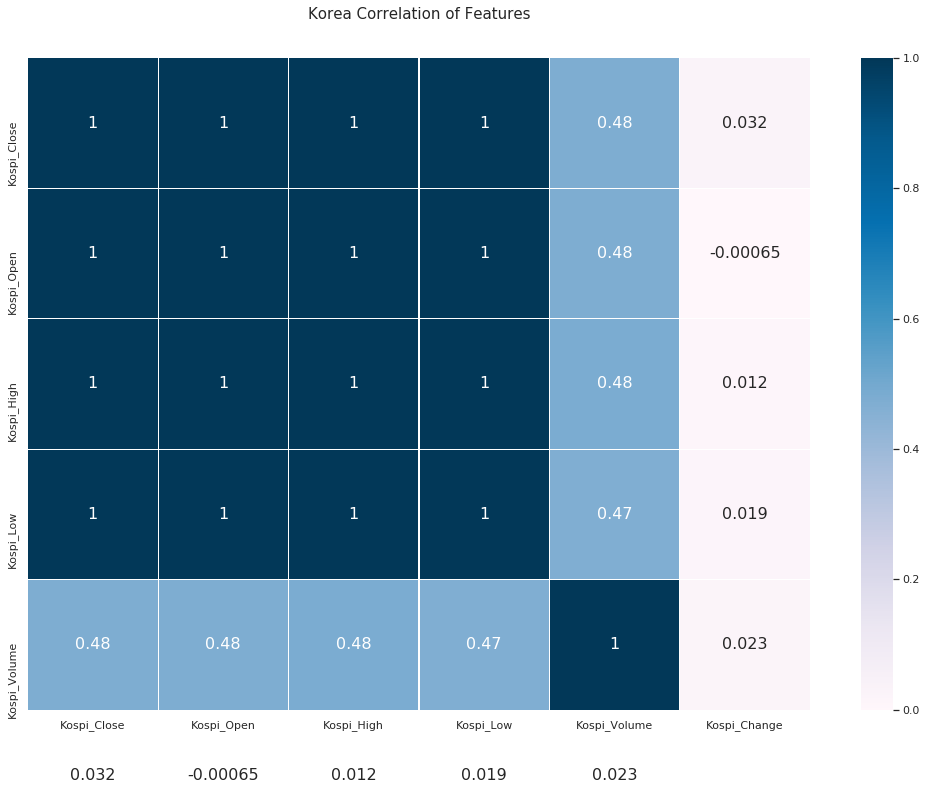
코스피가 환율 및 해외 주요 지수와 상관 관계에 있지 않을까? 라는 가설을 세웠다.
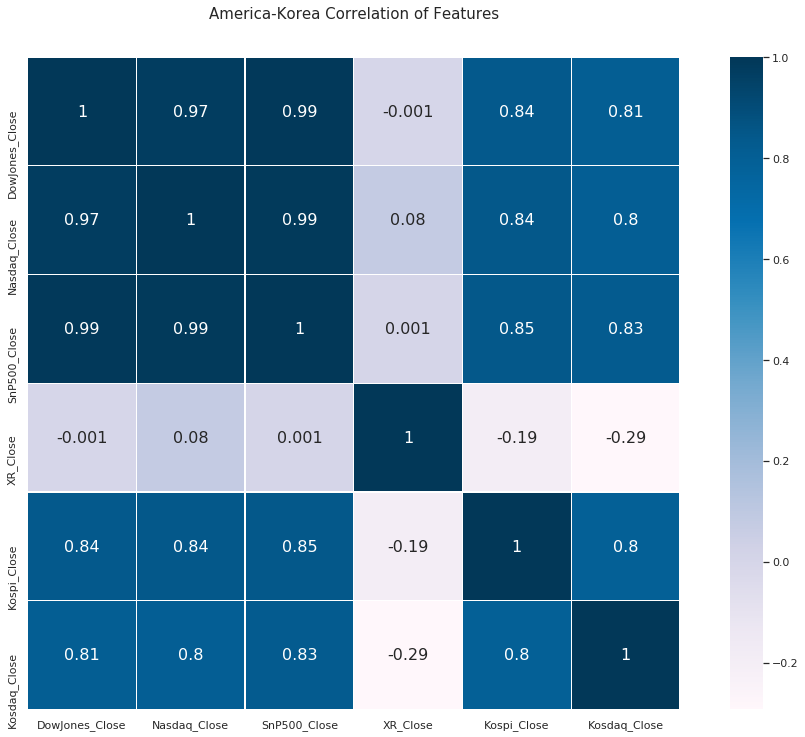
미국은 꽤나 코스피와 상관 계수가 높았다 !
환율은 생각보다 별 상관없나봄,,!
중국, 홍콩, 일본은?
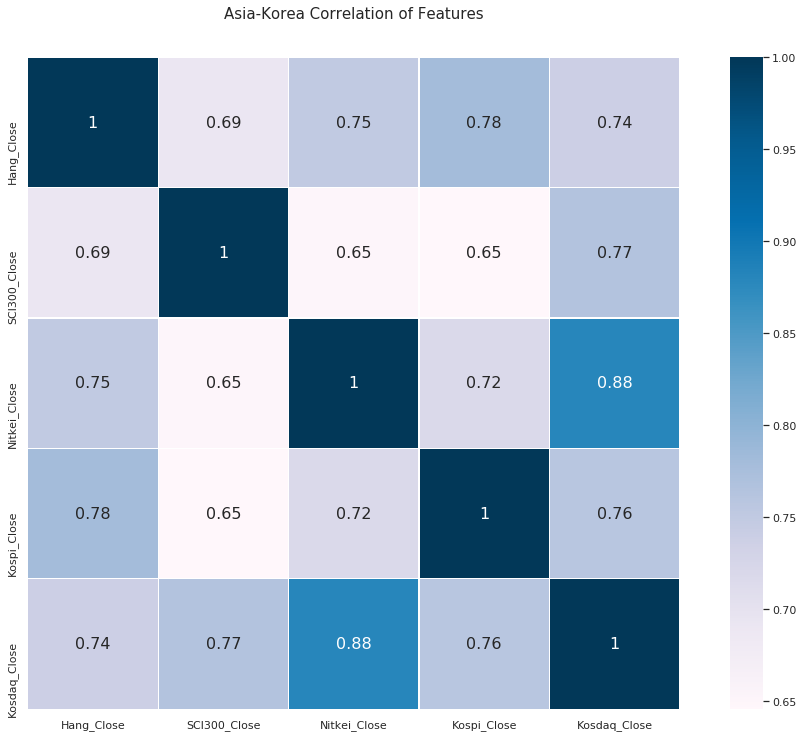
코스피는 코스닥보다 홍콩 지수의 항셍과 상관계수가 더 높음,,! ㄴㅇㄱ
그래프로 보면
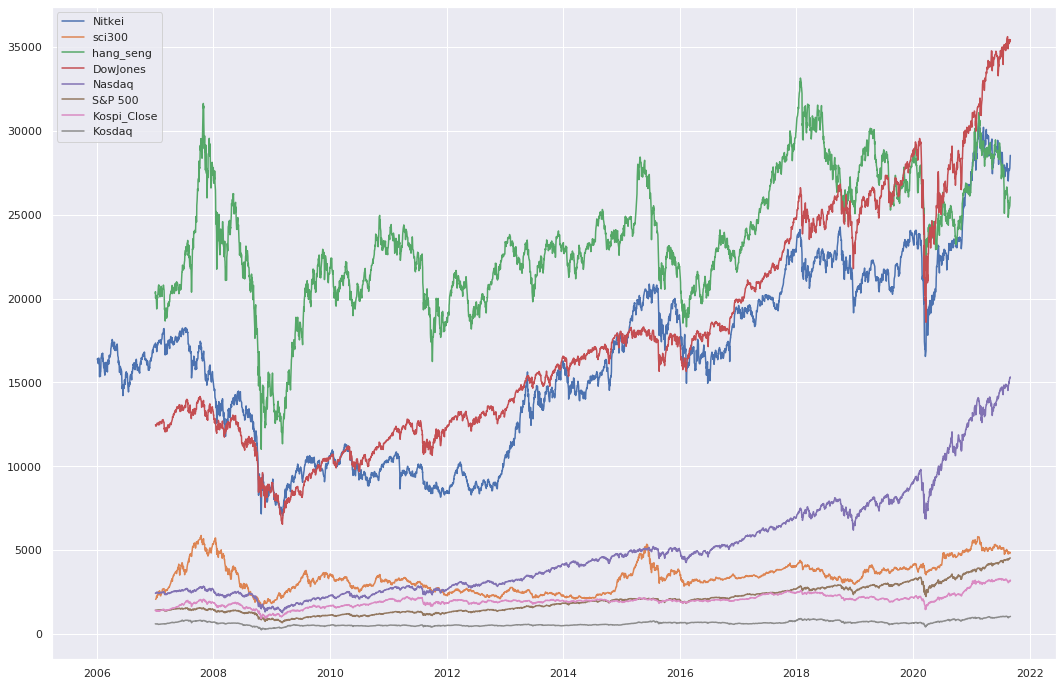
여기까지의 결론은 코스피 지수는 미 증시 지수와 상관 계수가 높고 코스닥보다는 홍콩 지수가 상관 계수가 높다.
(3) 전처리(Preprocessing)
전처리의 대부분은 데이터 모으고 합치고 바꾸고 결측치 채우고,,
fdr로 불러오는 데이터에는 한계가 있다. 나는 2000년부터 2021년까지의 데이터를 모아서 많은 실험을 하려고 했다,,!
하지만 fdr로 불러오는 데이터의 시작 일은 지수마다 달랐고 인베스팅 닷컴, 야후 파이낸스, 네이버/다음 금융에서 찾을 수 있는대로 다 긁어옴. 여기서 또 매일 최신 데이터는 업데이트 되어야 하므로 fdr데이터에 합치는 방법을 써야했다.
어려운 점은
1) 데이터의 양식이 다 다르다.
- 사이트마다 날짜를 표시하는 방식이나 이름을 표시하는 방식 그리고 columns의 위치가 달랐다. 사실 열의 위치가 다른 건 합치면서 자연스레 합쳐지니까 괜찮다. 하지만 시계열 데이터이니 만큼 시간에 대한 정리가 시급했다,,datetime과 pandas.Timestamp가 또 다르고 년월일로 표시된 건 또 바꿔줘야 했다.
2) 한국과 외국의 휴일은 다르다.
- 한국 장은 한국 휴일에 맞춰 휴장을 하고, 외국은 외국의 법에 따른다. 처음에는 두 날짜를 합치면서 어차피 우리나라 쉬면 종가는 그대로 유지고 하니까 그것만 잘 채워주면 되겠지라고 생각했다. 근데 그것도 그거대로 어려워서 헤매다가 결국 오랜 시간에 걸쳐 원점으로 돌아오고 나니 왜 하나 싶더라,, 우리나라 날짜로 맞춰서 진행했다.
3) 데이터를 여러 출처에서 구해오면 이상한 데이터가 꼭 있다.
- 데이터 많다고 중간에 생략한 부분을 지나치면 이상한 값으로부터 보복을 받는다,, 분명 아프지 않아야 되는데 진행도가 올라갈수록 기하급수적으로 데미지가 올라간다,, 확인 잘하기
(4) 특성 공학(Feature Engineering)
데이터를 서로 다른 곳에서 긁어오다 보니 상처가 난 건지, 뭐가 부족하다,,변동률이 없는 게 있었다.
변동률은 기본적으로 오늘 종가에서 전날 종가를 뺀 뒤 전날 종가로 나눠준다.
계산해보려 했지만 눈물만 흘렸다,,또륵
(5) 머신 러닝 모델링(Machine Learning Modeling)
베이스모델은 선형회귀 모델이었다. RandomForest모델과 Boost 모델들을 썼지만, 뭔가가 잘못됐는지 올바른 값이 나오지 않았다. 다시 방향을 잡아서 제대로 해봐야겠다,,
(6) 시각화(Visualization)
PDP Plot이라든가 SHAP Plot등 쓰고싶은 게 많았지만 제대로 표현하지 못했다,,
ps. 대회의 방향과 조금 다르게 구현하다보니 어색한 부분도 있고, 시계열은 처음이기도해서 서툴렀던 것 같다.
발표 자료에서도 소리가 나오지 않아 속상해하고 있었는데 그래도 같은 조원들이 ppt 스크립트 기반으로 평가를
내려주셔서 감사했다.
'코드스테이츠 AI 부트캠프' 카테고리의 다른 글
| [EDA] 탐색적 데이터 분석 (2) | 2021.08.30 |
|---|---|
| [EP.0] 코드스테이츠 AI 부트캠프 신청 (0) | 2021.07.06 |
